
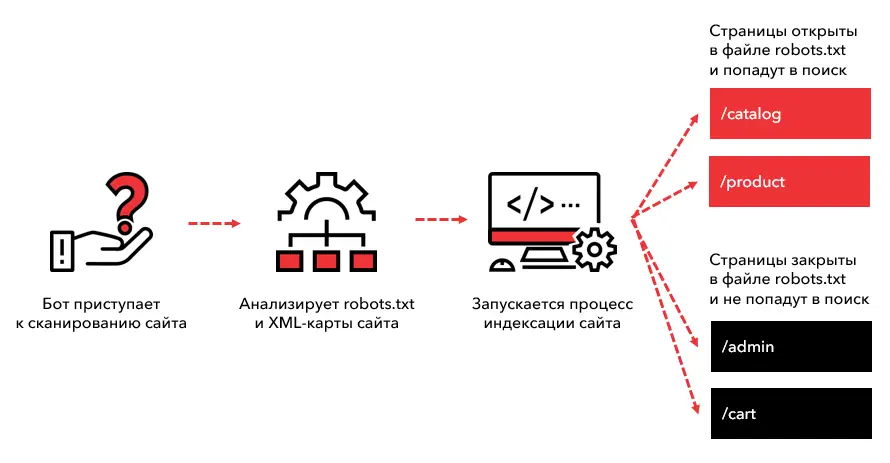
Когда мы заходим на сайт, мы надеемся, что все его страницы доступны для поисковых систем и могут быть легко найдены. Однако, иногда бывает необходимо скрыть определенные части сайта от поисковых роботов. Для этого существует файл robots.txt.
Robots.txt – это текстовый файл, который говорит поисковым роботам, какие страницы или разделы сайта следует индексировать, а какие нет. Если веб-мастер не хочет, чтобы разделы его сайта попадали в индекс поисковой выдачи, он может указать это в файле robots.txt.
Использование robots.txt позволяет контролировать доступ к частям сайта, которые могут быть неинтересны пользователям или поисковым системам. Например, создание отдельного раздела для внутренних административных функций и запрещение индексации его страниц поможет упростить навигацию на сайте и обеспечить безопасность данных.
Защита конфиденциальной информации
В наше время конфиденциальность информации играет огромную роль, особенно в онлайн сфере. От различных веб-роботов и поисковых систем зависит, насколько безопасной останется ваша информация, а какие данные попадут в общий доступ. Для обеспечения защиты конфиденциальности и контроля над информацией используется файл robots.txt.
Файл robots.txt позволяет вам указать роботам, какие страницы вашего сайта стоит индексировать и какими они должны быть доступны. При настройке robots.txt можно скрыть от роботов различные разделы сайта, которые содержат конфиденциальную информацию или требуют авторизации пользователей.
Типы конфиденциальной информации
Различные сайты могут содержать разные типы конфиденциальной информации, которую необходимо скрыть от роботов. К таким типам информации можно отнести:
- Личные данные пользователей, такие как имена, адреса, номера телефонов или электронных почт;
- Финансовую информацию, включая банковские данные и номера кредитных карт;
- Медицинскую информацию, которая является строго конфиденциальной;
- Коммерческую информацию, включая планы и стратегии бизнеса;
- Авторские права и интеллектуальную собственность.
Роботы, которые обрабатывают файл robots.txt, должны уважать основные принципы конфиденциальности и не индексировать или раскрывать чувствительную информацию.
Ограничение индексирования нежелательного контента
Для того чтобы предотвратить индексацию нежелательного контента с помощью robots.txt, необходимо правильно настроить этот файл на сайте. В нем можно указать какие страницы или разделы сайта не должны попадать в поисковую выдачу.
Один из способов ограничения индексирования нежелательного контента — это запретить его для всех поисковых роботов с помощью директивы «Disallow». Например, если на сайте есть раздел, содержащий личные данные или коммерческую информацию, которую вы не хотите видеть в поисковой выдаче, можно добавить следующую строку в robots.txt:
User-agent: * Disallow: /нежелательный_раздел/
Здесь:
- User-agent: * — указывает, что правило действует для всех поисковых роботов;
- Disallow: /нежелательный_раздел/ — указывает, что раздел «нежелательный_раздел» не должен индексироваться.
Таким образом, поисковые роботы, следуя правилам, указанным в robots.txt, не будут индексировать страницы этого раздела.
Блокировка сканеров и спам-ботов
Для блокировки конкретных URL-адресов вы можете использовать директиву Disallow. Она позволяет указать роботу запретить доступ к определенным URL-адресам. Например, если вы хотите заблокировать доступ ко всему содержимому папки «спам», вы можете использовать следующую директиву:
User-agent: * Disallow: /spam/
Это пример запрета доступа ко всему содержимому папки «спам». Звездочка (*) в директиве User-agent означает, что запрет будет действовать для любых роботов. Директива Disallow указывает, какой URL-адрес должен быть заблокирован.
Важно отметить, что спам-боты и сканеры могут проигнорировать файл robots.txt и продолжить сканирование и спам. Поэтому, помимо использования robots.txt, рекомендуется принимать дополнительные меры для борьбы со сканерами и спам-ботами, такие как настройка серверного фаервола или использование специальных плагинов для защиты от спама.
Итак, блокировка сканеров и спам-ботов — важная часть настройки robots.txt. Ее цель — минимизировать негативное влияние сканеров и спам-ботов на работу вашего сайта и защитить его от множества ненужных запросов. Помните, что файл robots.txt — это всего лишь указание, которое рекомендуется соблюдать роботам. Некоторые сканеры и спам-боты могут его проигнорировать, поэтому рекомендуется принимать и другие меры для защиты от нежелательного трафика.
Наши партнеры: